El tamaño de la muestra o cálculo de número de observaciones es un proceso vital en la etapa de cronometraje, dado que de este depende en gran medida el nivel de confianza del estudio de tiempos. Este proceso tiene como objetivo determinar el valor del promedio representativo para cada elemento.
Los métodos más utilizados para determinar el número de observaciones son:
- Método Estadístico
- Método Tradicional
Método estadístico
El método estadístico requiere que se efectuen cierto número de observaciones preliminares (n’), para luego poder aplicar la siguiente fórmula:
NIVEL DE CONFIANZA DEL 95,45% Y UN MÁRGEN DE ERROR DE ± 5%

Siendo:
n = Tamaño de la muestra que deseamos calcular (número de observaciones)
n’ = Número de observaciones del estudio preliminar
Σ = Suma de los valores
x = Valor de las observaciones.
40 = Constante para un nivel de confianza de 94,45%
Ejemplo:
Se realizan 5 observaciones preliminares, los valores de los respectivos tiempos transcurridos en centésimas de minuto son: 8, 7, 8, 8, 7. Ahora pasaremos a calcular los cuadrados que nos pide la fórmula:
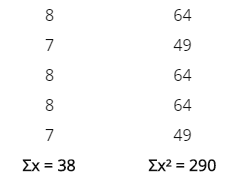
n’ = 5
Sustituyendo estos valores en la fórmula anterior tendremos el valor de n:

Dado que el número de observaciones preliminares (5) es inferior al requerido (7), debe aumentarse el tamaño de las observaciones preliminares, luego recalcular n. Puede ser que en recálculo se determine que la cantidad de 7 observaciones sean suficientes.
Intervalos de confianza
Un intervalo de confianza nos va a permitir calcular dos valores alrededor de una media muestral (uno superior y otro inferior). Estos valores van a acotar un rango dentro del cual, con una determinada probabilidad, se va a localizar el parámetro poblacional.
Intervalo de confianza = media +- margen de error
Conocer el verdadero poblacional, por lo general, suele ser algo muy complicado. Pensemos en una población de 4 millones de personas. ¿Podríamos saber el gasto medio en consumo por hogar de esa población? En principio sí. Simplemente tendríamos que hacer una encuesta entre todos los hogares y calcular la media. Sin embargo, seguir ese proceso sería tremendamente laborioso y complicaría bastante el estudio.
Ante situaciones así, se hace más factible seleccionar una muestra estadística. Por ejemplo, 500 personas. Y sobre dicha muestra, calcular la media. Aunque seguiríamos sin saber el verdadero valor poblacional, podríamos suponer que este se va a situar cerca del valor muestral. A esa media le sumamos el margen de error y tenemos un valor del intervalo de confianza. Por otro lado, le restamos a la media ese margen de error y tendremos otro valor. Entre esos dos valores estará la media poblacional.
Muestras definitivas
Confección de muestras físicas de etiquetas tejidas; Antes de la fabricación de las etiquetas, el cliente recibe muestras definitivas, fabricadas con los mismos colores, diseños y materiales que tendrán las etiquetas fabricadas posteriormente según el pedido.
Estadísticas descriptivas
Se denomina estadística descriptiva a las cantidades matemáticos (tales como la media, mediana, desviación estándar) que resumen e interpretan algunas de las propiedades de un conjunto de datos (muestra), pero que no miden las propiedades de la población de la que se extrajo la muestra (ocupándose de este extremo la estadística inferencial).

Las estadísticas descriptivas son coeficientes descriptivos que permiten mostrar información resumida de un conjunto de datos, que puede ser una representación de toda la población o una muestra de ella. La estadística descriptiva se descompone en las medidas de tendencia central y medidas de variabilidad, o dispersión. Medidas de tendencia central incluyen la media, la mediana y la moda, mientras que las medidas de la variabilidad incluyen la desviación estándar o la varianza, el mínimo y el máximo de la variable, y la curtosis y asimetría.
